To say I’ve been on a long hiatus since my last post would be an understatement. During that time, I snagged a Master’s and PhD in Computer Science, moved into a couple new positions at UNH, and worked on a number of projects. Things have been busy to say the least, but now that a semi-normal schedule is finally starting to return to my life, I really want to focus on things that are fulfilling and meaningful. One of these things is dedicating time to personal projects again and sharing them with the community. I love seeing what other folks are working on, and I want to contribute and give back as well. I have a new game I’ve been working on for the last six months that I hope people will really enjoy playing, and allow them to create their own virtual experiences in a very RETRO style. More details on that very soon!
In the meantime, I wanted to share two tutorial videos that might be able to help folks in the bioinformatics community. The first is a video on how to use PALADIN, a tool for characterizing metagenome shotgun data (see paper here). The second is a video on using the Linux program tmux, a tool for multiplexing multiple terminal sessions. Very useful for those who spend all day in a terminal window like myself!
I think one of the things I love about attending grad school so much is all the opportunity for collaboration – especially across disciplines. To be surrounded by so many people with passion for these different topics, all working toward discovery and creation – it’s really an amazing experience. One particular interdisciplinary area I’ve fallen in love with is bioinformatics. I’ve had interest in computational biology for a long time, as can be seen with my work with SynthNet – but this has been my first opportunity to work first hand with others in these areas – as well as experts squarely in the biology fields, which has been an extremely helpful learning experience.
Enter Bioinformatics
I’ve found bioinformatics, genomics, proteomics, etc to be especially interesting, as there are such a ridiculous number of inherent parallelisms between what occurs in nature and what we’ve discovered and devised in Computer Science. Obviously the underlying Turing-complete, algorithmic nature of things drives them both, but it’s still awe inspiring to see these processes in genetics happening naturally, and then be able to make predictions using the same rules that one would in CS.
PALADIN: software for rapid functional characterization of metagenomes
One such area in bioinformatics that we’ve been focused on for the last 6 months or so is the problem of identifying genes/proteins from metagenomic read sets. In a metagenomic sample, you have many organisms present, perhaps thousands – all these small pieces of DNA mixed together – and it presents a problem when you want to actually identify what was in there. Or more aptly, in our case, the function of what was in there. I love making the analogy to taking 500 different jigsaw puzzle boxes, opening them up, and dumping them all together. To make things worse, though the puzzles are different, some of them feature a lot of the same themes – flowers, grass, sky, etc. But let’s step it up – you also lose some pieces in the process, some get damaged and misshaped, and there are duplicates of others. Now try reconstructing all 500 puzzles – not so easy!
While there are lots of strategies and ways for computers to “reconstruct these puzzle pieces”, so to speak – many of them are slow and have inherent issues. We attempt to solve these speed and other issues with our new software, PALADIN, that I’ve been lucky enough to be the lead developer of, though it’s a 100% team effort for this kind of project
I won’t go into the full details of the software here, but if you’d like to learn more about it, our team, and details on the upcoming manuscript, you can read more about it on Professor Matt MacManes’ blog post.
First year of grad school done, second one about to start! It’s been an absolutely amazing experience so far – more to come about the bioinformatics aspect of it in future posts.
For this post, I wanted to discuss one of the plugins I developed during my scientific visualization class, and my newfound (at that time) love for the VTK framework and ParaView.
Visualize Everything!
If you haven’t encountered it before, VTK (Visualization Tool Kit) is a framework developed by Kitware for handling the entire pipeline process from consuming organized data, processing, filtering, visualizing, and/or exporting. They’ve also developed an accompanying GUI application for easily manipulating VTK, called ParaView. Both of these packages have been around for many years, but I had (unfortunately) not been exposed to them until my class – however, after using the software for a short time, I quickly realized how ridiculously powerful the framework is, and I really wanted to do more work with it.
The UNH Granite Scientific Database System
Being an open source pipeline, one of the places VTK shines is in its modularity and expandability – almost every part of the pipeline can call a custom plugin. I decided to take advantage of this – UNH has a custom Java library named The Granite Scientific Database System (Granite SDB), which provides a comprehensive set of classes for accessing multidimensional scientific data. It was originally developed, and continues to be maintained by, UNH Professor Daniel Bergeron, and has been expanded over the years by a number of students. While it is very powerful in its capabilities, it is designed strictly as a processing and storage library – it leaves the actual visualization routines to the developer. With this in mind, I thought it would be a perfect match to write a Granite plugin for ParaView.
Single Resolution Data
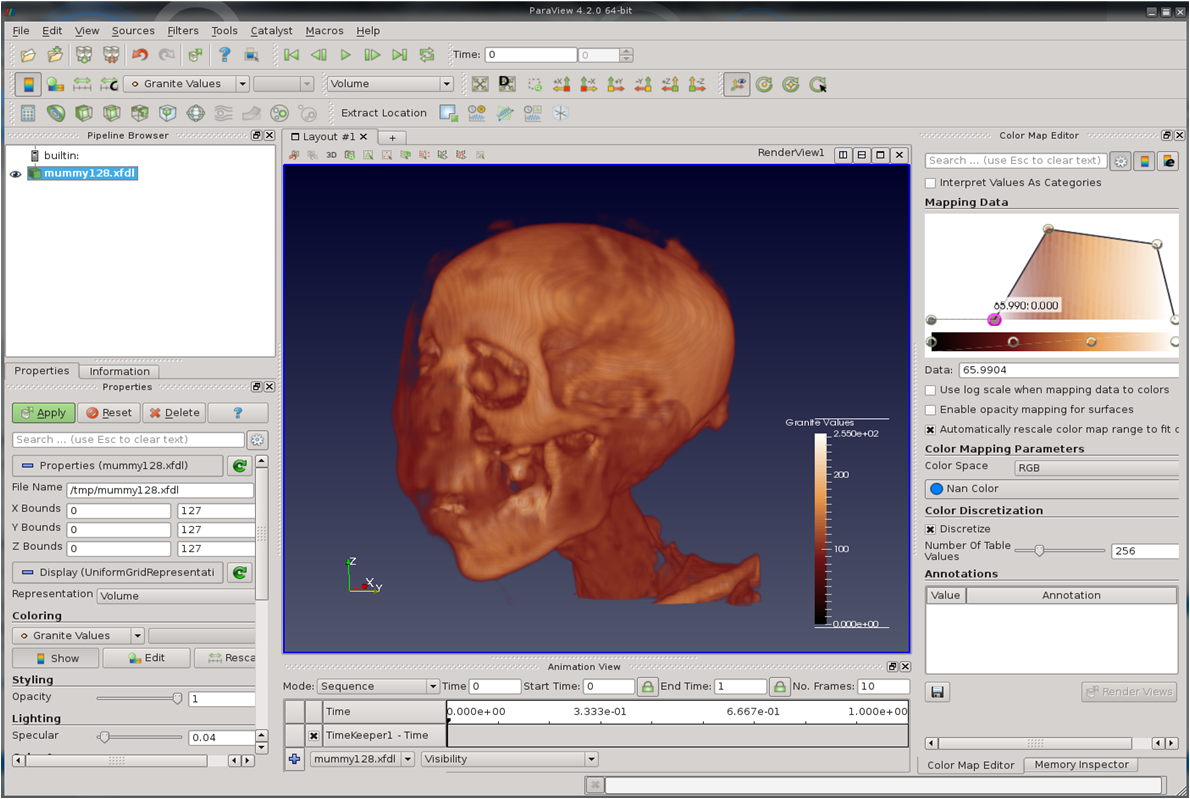
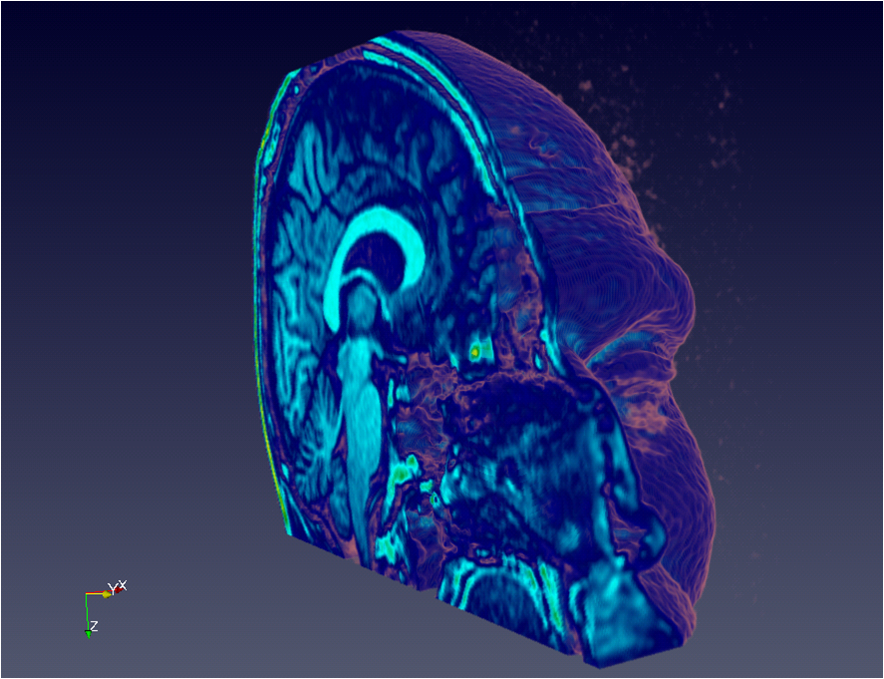
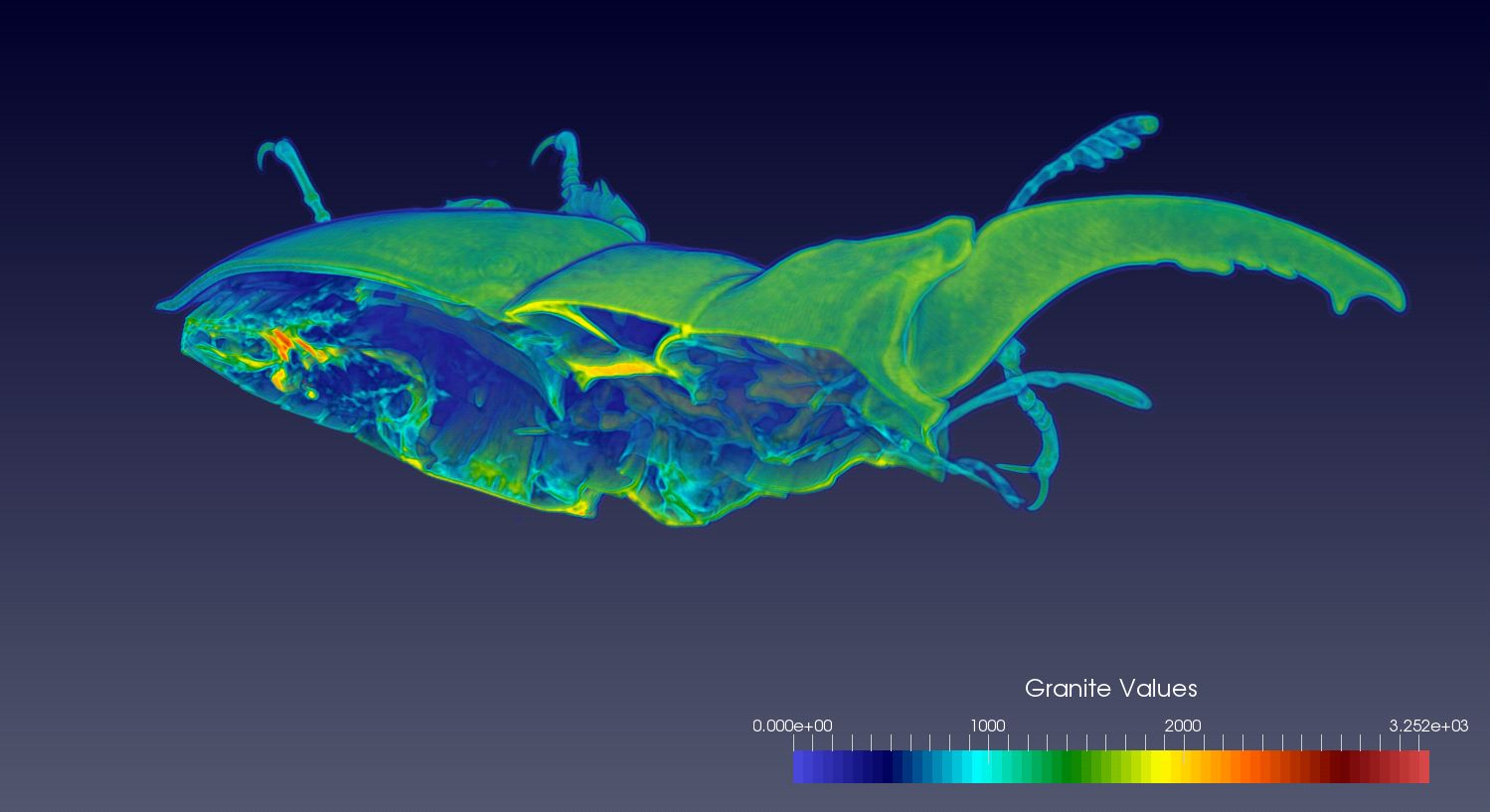
Before diving head first into the full capabilities of VTK, I decided to start with a simple read plugin for working with single resolution data. Since there are such a large number of medical images/datasets available in on the net (CT and MRI scans), especially in DICOM format, I decided to start with loading this data into Granite, and then seeing if I could visualize this with ParaView via the plugin. After only a few days, I was able to get perfect results! Here are some examples of sets loaded through the plugin:
Mummy (CT)
Head (MRI)
Beetle (Micro CT)
Cool stuff! With that working, I wanted to tackle more…
Multi and Adaptive Resolution
One of the challenges when visualizing data, especially large amounts of data, are the limitations of the underlying hardware. By necessity, different methods must be employed to only visualize the relevant portions, whether it be the amount rendered, areas rendered, streaming portions at a time, etc. Along these lines, VTK offers a newer portion of the pipeline that allows for streaming blocks of overlapping data at different resolutions. In this way, only specific areas (dependent on the viewport focus – direction and zoom) will be rendered, and done so in a streaming manner, so the user can continue to manipulate the program while searching for areas of interest in the render.
Long story short, the following video is the end result of the plugin supporting overlapping AMR. In this demo, the plugin resets the visualization every time the camera is rotated to demonstrate clearly how it operates. As can be seen, the data starts out at a very low resolution for quick rendering, then continues to resolve to higher and higher resolutions, centered around the area being viewed, as data is streamed from the Granite, through the plugin, into VTK. I used the same mummy CT scan as shown above.
As can be seen by the post dates, I’ve experienced another one of my blogging hiatuses. This was due mostly to going into crunch mode trying to finish up emissary RT – I really needed to get it wrapped up before September, as I needed to have my schedule wide open by the start of the month. The reason why – I got accepted to grad school! I’ll be starting the program to get my Masters in Computer Science in a few days, and needed to get this final item checked off my list. I’m very excited for school, but equally happy to be finished with emissary RT – it was a fun project that I’ve long had the idea for, but after 2 years of development, I was ready for it to be complete.
In other news, I’ve really been diving back into my gaming roots lately. I recently finished listening to Masters of Doom on audiobook (biography of John Carmack and Romero – get it NOW if you haven’t read it already!), and along with bringing back a HUGE slew of memories from gaming in the 90s (shareware like Commander Keen, BBSes, the start of the Internet, etc), it was also incredibly inspiring to hear the story of some passionate developers following their dreams and love of development. Along with this, I also finally started playing with Unity, which I’ve been meaning to try for a while. Long story short, I am completely hooked on the game engine, and incredibly ramped up to start a new game (it’s been too long since my last one), so along with working more on SynthNet, this will be my next big project. More details soon!
After many, many years (I’ve lost count at this point) of faithful service , I’ve finally refreshed the Synthetic Dreams website into something a little more modern and functional. Take a look if you’ve got a moment, it’s built on Drupal (of course), and features a responsive design for those browsing on the go.
Additionally, after being in development for almost 2 years, I’ve finally finished emissary RT – an ODBC driver that allows you to access a whole slew of things, from your file system to DHCP and DNS. The upshot of this is allowing you to use SQL (or the GUI in ODBC apps) to manipulate files and services in very powerful and automation-friendly ways. You can check out the full details on the Synthetic Dreams site as well.
I realized while responding to some comments that I completely forgot to mention some exciting news! Last month, I was fortunate enough to have an article featured on the Qualcomm Spark website, “Can We Grow Artificial Intelligence?” It explores some of the capabilities we currently have of emulating DNA and biological growth, and incorporating these abilities into our normal programming tools to develop all sorts of AI. I had a lot of fun writing it, as well as reading the other articles featured on the site. So many exciting technologies on the horizon (or already here!)
Though I have fun working on SynthNet and other projects at night, during the day I fill the role of mild-mannered network administrator at the Manchester-Boston Regional Airport (actually, the day job is quite a bit of fun as well). One of the ongoing projects I’ve taken on is adding all of our various Intranet-oriented services into a single platform for central management, easier use, and cost effectiveness. As mentioned in a previous article (linked to below, see NMS Integration), I knew Drupal was the right candidate for the job, simply due to the sheer number of modules available for a wide array of functionality, paired with constant patching and updates from the open source community. We needed a versatile, sustainable solution that was completely customizable but wasn’t going to break the bank.
The Mission
The goal of our Drupal Intranet site was to provide the following functionality:
PDF Document Management System
Categorization, customized security, OCR
Desktop integrated uploads
Integration with asset management system
Asset Management System
Inventory database
Barcode tracking
Integration with our NMS (Zenoss)
Integration with Document Management System (connect item with procurement documents such as invoices and purchase orders)
Automated scanning/entry of values for computer-type assets (CPU/Memory/HD Size/MAC Address/etc)
Physical network information (For network devices, switch and port device is connected to)
For network switches, automated configuration backups
Help Desk (ticketing, email integration, due dates, ownership, etc)
Public Address System integration (Allow listening to PA System)
Active Directory Integration (Users, groups, and security controlled from Windows AD)
Other non-exciting generic databases (phone directories, etc)
Implementation
Amazingly enough, the core abilities of Drupal covered the vast majority of the required functionality out of the box. By making use of custom content types with CCK fields, Taxonomy, Views, and Panels, the typical database functionality (entry, summary table listings, sorting, searching, filtering, etc) of the above items was reproduced easily. However, specialized modules and custom coding was necessary for the following parts:
Customized Security – Security was achieved for the most part via Taxonomy Access Control and Content Access. TAC allowed us to control access to content based on user roles and categorization of said content (e.g. a user who was a member of the “executive staff” role would have access to documents with a specific taxonomy field set to “sensitive information”, whereas other users would not). Additionally, Content Access allows you to further refine access down to the specific node level, so each document can have individual security assigned to it.
OCR – This was the one of the few areas we chose to delve into a commercial product. While there are some open source solutions out there, some of the commercial engines are still considerably more accurate, including the one we choose, ABBYY. They make a Linux version of the software that can be driven via the shell. With a little custom coding, we have the ABBYY software running on each PDF upload, turning it into an indexed PDF. A preview of the document is shown in flash format by first creating a swf version (using pdf2swf), then using FlexPaper/SWF Tools.
Linking Documents – This was performed with node references and the Node Reference Explorer module, allowing a user friendly popup dialogs to choose the content to link to.
Desktop Integration – Instead of going through the full steps of creating a new node each time, choosing a file to upload, filling in fields, etc, we wanted the user to be able to right click a PDF file on their desktop, and select “Send To -> Document Archive” from Windows. For this, we did end up doing a custom .NET application that established an HTTP connection to the Drupal site and POSTed the files to it. Design of this application is an article in itself (maybe soon!).
Barcoding – This was the last place we used a commercial product simply due to the close integration with our barcode printers (Zebra) – we wanted to stick with the ZebraDesigner product. However, one of the options in the product is to accept the ID of the barcode from an outside source (text/xml/etc), so this was simply a matter of having Drupal put the appropriate ID of the current hardware item into a file and automating ZebraDesigner to open and print it.
NMS (Zenoss) Integration – The article of how we accomplished this can be found here.
Automated Switch Configuration Backups and Network Tracking – This just took a little custom coding and was not as difficult as it might seem. Once all our network switches were entered into the asset management system and we had each IP address, during the Drupal cron hook, we had the module cURL the config via the web interface of the switch by feeding it a SHOW STARTUP-CONFIG command (e.g. http://IP/level/15/exec/-/show/startup-config/CR) – which was saved and attached to the node. Additionally, we grabbed the MAC database off each switch (SHOW MAC-ADDRESS-TABLE), and parsed that, comparing the MAC addresses on each asset to each switch port, and recording the switch/port location into each asset. We could now see where each device on the network was connected. A more detailed description of the exact process used for this may also be a future article.
Help Desk – While this could have been accomplished with a custom content type and views, we chose to make use of the Support Ticketing Module, as it had some added benefits (graphs, email integration, etc)
Public Address System – Our PA system can generate ICECast streams of its audio. We picked these up using the FFMp3 flash MP3 Live Stream Player.
Automated Gathering of Hardware Info – For this, we made use of a free product called WinAudit loaded into the AD login scripts. WinAudit will take a full accounting of pretty much everything on a computer (hardware, software, licenses, etc) and dump them to a csv/xml file. We have all our AD machines taking audit during logins, then dumping these files to a central location for Drupal to update the asset database during the cronjob.
Active Directory Integration – The first step was to ensure the apache server itself was a domain member, which we accomplished through the standard samba/winbind configurations. We then setup the PAM Authentication module which allowed the Drupal login to make use of the PHP PAM package, which ultimately allows it to use standard Linux PAM authentication – which once integrated into AD, includes all AD accounts/groups. A little custom coding was also done to ensure matching Drupal roles were created for each AD group a user was a part of – allowing us to control access with Drupal (see #1 above) via AD groups.
There was a liberal dose of code within a custom module to glue some of the pieces together in a clean fashion, but overall the system works really smoothly, even with heavy use. And the best part is, it consists of mainly free software, which is awesome considering how much we would have paid had we gone completely commercial for everything.
Please feel free to shoot me any specific questions about functionality if you have them – there were a number of details I didn’t want to bog the article down with, but I’d be happy to share my experiences.
In this uber-connected, social media driven world, it seems like the time between when an idea is born and when it completely saturates the Internet twenty times over is almost nil. While this does mean seeing Dramatic Chipmunk and Nyan Cat until the point of retinal damage, it also has the benefit of introducing the masses to really cool ideas and projects from all around the globe. It means more people sharing their creations, which is a win-win for everyone.
Because of this mass spread of information, it always surprises me how many people are unfamiliar with the demoscene. Having grown up a Commodore 64 (and later Amiga) kid who hung out on BBSes, intros and demos were always a part of my computer world. At that time, they were amazing, mysterious creations, made by programmers with futuristic-sounding handles from far away countries. As I grew older, I started to not only befriend many sceners, but also think more about both the Computer Science and art that actually went into these – and my amazement only increased. Now I do everything I can to show off these programmatic, musical, and artistic feats to anyone who will watch.
The Scene
To quote Wikipedia, “The demoscene is a computer art subculture that specializes in producing demos, which are audio-visual presentations that run in real-time on a computer. The main goal of a demo is to show off programming, artistic, and musical skills.” Originally, they started as shout-outs and other introductions in game cracks on 8-bit computers, showing off programming skill. They quickly bloomed into an entire culture of demogroups, competitions, parties, boards, etc – and is still going strong today with a strong European core (though still prevalent in the US!). I encourage you to learn more about all the awesome history behind the scene – there is more than can be covered in one blog post.
Favorite Demos
While the history is interesting, what is more important are the demos themselves! Below I’ve included 4 of my favorite demos. The first two are 64K PC demos. When I say 64K, I mean the entire demo is 64K big. Graphics, music, code – everything. This is procedural programming on steroids – artistic and algorithmic wonderment.
The second two are for the Commodore 64. While they are more limited by the hardware, the talent still shines through. The first is a great example of an amazing musical score, and the second is unbelievable coding and use of the C64 hardware, making it look more like a 16-bit machine.
This is just a taste of what has come out over the years – I encourage you to take a look at sites like pouet.net and The Commodore Scene Database for some more examples. Be prepared to be amazed!
Recently, I started talking with my girlfriend about the idea of writing a life plan. The idea is similar in nature to a business plan, but instead of outlining the structure, mission statements, and strategies of a financial venture, you’re focused on the values, goals, and eventualities of your life as a whole. I’ve researched a bit online, and the more I thought about it, the more I realized what a completely awesome tool a life plan could be – not only for organizing your life, but just the process of writing one can really illuminate and flesh out life-goals. More importantly though, as I realized by talking with my friends, it can truly be a living document, one that grows over time as life, values, and situations change.
Though I am only in the planning stages now of what I want to include in my plan, I know before I put a single word down that there are two items that I will inevitably focus on. The first is one of my true passions in life – creating. Specifically, creating through computer science – games, AI, network utilities, or anything. But ultimately I know this isn’t truly fulfilling. I read article after tweet after blog post about software development and computer science – and some writing inspires me, and some falls flat. It took me a while to figure out why, and as of late I realize more why that is. Which brings me to the second item I will focus on – helping the world. If I have a limited time on this big, blue globe, I want to do whatever I can to ensure that hopefully, at least in some small part, my creations will make the life a better place. This – and making connections with other people who want to use their awesome skills to do some serious good! I’m lucky enough to lots of friends with this attitude, and I’d love to make more.
Resources
To say there are a lot of amazing organizations out there changing the world on a daily basis would be an understatement – our lives change constantly with the evolution of social networks, mobile devices, and interconnectivity. And while many of these changes attack very real problems and improve quality of life, there is still infinite amounts of space to effect positive change – still countless opportunities to do good. And I think it’s important to deliberately focus on these items as a core goal. I’ve recently begun to search online for resources and other like-minded buddies to help in this quest – and I’ve found a number in academia, as well awesome sites like TED that have some truly brilliant people focused on these very issues.
If you know of any other resources that talk about helping the world through computer science or other technology-driven philanthropy, please feel free to send them this way!
Or if you have any experience with writing a life plan or steps you’ve taken to clarify goals for yourself, please feel free to drop me a line!
I know there are other people much smarter than me who have tackled these areas before, so I’d love any guidance or tips. I hope to continue to post on these subjects as I learn more and make further connections.
James Pearn at artificialbrains.com was nice enough to include SynthNet in his list of resources related to artificial intelligence. Check out his site if you get a moment, it serves as a well laid-out directory of many neural network and other artificial intelligence projects going on around the world, as well as job listings. Very cool site – thanks James!
Hello - and thanks for visiting my site! I maintain ToniWestbrook.com to share information and projects with others with a passion for applying computer science in creative ways. Let's make the world a better and more beautiful place through computing! | More about Toni »